
Add column as a key or INCLUDE column in the index?
SELECT --> INCLUDE column, WHERE --> Key column

Let’s first understand a few terms before going ahead:
Key columns: Columns in non-clustered index
Key lookups: When query contains a column that is not part of non-clustered index, then with the help of row-id, it does a lookup to the clustered index to retrieve data for that column. This is called a key lookup. This is an expensive operation. To avoid this extra cost, we can include that column to the non-clustered index.
Covering index: Index that provides all the information needed for a query, which means the index covers a query, is called a covering index. In order to avoid key lookups, a column is added as an INCLUDE column in the non-clustered index.
It is good to have a non-clustered index that can cover a query, otherwise it has to go to clustered index and fetch data for columns that are not present in non-clustered index. This is called key lookup. When the Optimizer expects it has to do a lot of key lookups, then it doesn’t use a non-clustered index but chooses to use a clustered index to avoid the key lookups. The cost is high in this case, since scanning a clustered index means scanning the entire table aka more columns and more pages, whereas if we are able to cover a query using a non-clustered index, then the engine reads a lot less columns and lesser pages.
How do we get the index to cover a query?
When all columns in WHERE, GROUP BY, ORDER BY, SELECT are in the non-clustered index, then the query is covered. There won’t be any lookups to the clustered index. Imagine, there is a column in SELECT clause that is not present in non-clustered index, in order to prevent the key lookups, we can add that column to the non-clustered index.
The next question comes in place.
How do we determine if that column should be added as a key column or INCLUDE column in non-clustered index?
To determine that, let us first understand how a non-clustered index looks like. Imagine an inverted tree where you have root on the top and leaves at the bottom. non-clustered index contains a root level, one or many intermediate level pages and many leaf level pages in the bottom, as in the picture below.
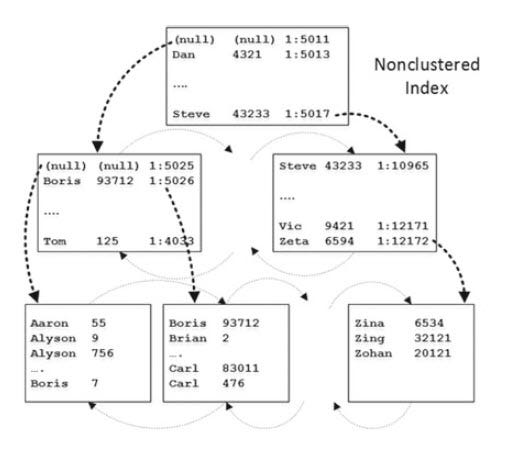
Leaf level(Bottom most) contains all rows of key columns of non-clustered index, in this case let’s assume non-clustered index key columns are Name and ID. This is sorted by the first key column which is Name. Intermediate level(One above bottom) contains one row from every leaf page. That row is the minimum key value of that leaf level page. Let's call this intermediate level L1 for understanding purposes. L1 contains Name, ID and the physical address in each page. The next intermediate level (L2, which is above L1) contains one row(minimum key value) from every page of intermediate level L1. And next intermediate level L3 contains one row from every page in L2. As it keeps building the intermediate levels, finally, it will end up with just one page on the top(root level) and this will contain one row from every page of its immediate intermediate page(one below root).
In summary, leaf level contains all rows of the key columns in non-clustered index. It is based on the sorting order of the first few key columns, especially first column in non-clustered index being the most important one because that is how the index is primarily sorted. So choosing the first column is very important and this column should also be the most used in WHERE clause of queries using that non-clustered index. To summarize, we saw how a non-clustered index looks like. Now, let’s look at how an index with an included column.
When a column is added as an INCLUDE, this is how the non-clustered index looks like:
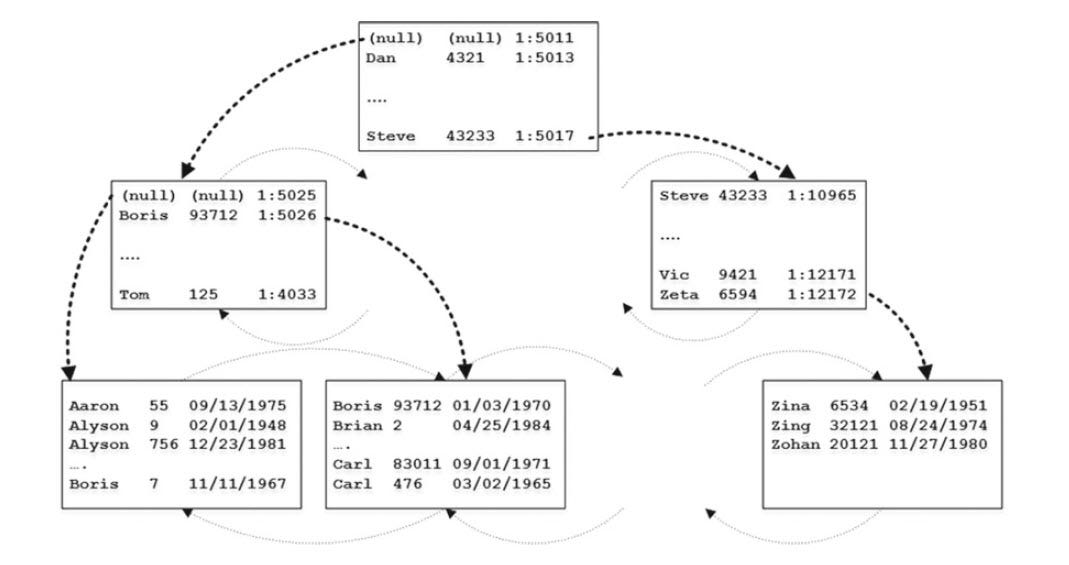
You can see from the picture that, rows of INCLUDE column are added only at the leaf level of the index and not present in the intermediate level or root level of the index. And this column data is not sorted and therefore not SARGable.
Now let's discuss the 2 scenarios:
Scenario 1:
When you have a column in the filter clause, it is better to have the values SARGable, so Optimizer can go seek right at the page where the row is located and retrieve the values. For this to happen, it is important to have the rows of this column sorted. Row data can get sorted only if the column is part of the index key columns. Key columns get added to root and intermediate level pages of the index.
From this we can conclude that, if a column is in the filter clause, then it can be added as part of the key columns in the index. Determining which position in the index this column needs to be added depends on the pattern of queries and how many queries are using this index and which key columns are being used the most.
Scenario 2:
When you have a column in the SELECT, then this column can be added as an INCLUDE column, since this column data doesn't have to be sorted and all you need is to have the data of this column in the index so lookups to the clustered index(which has all columns)can be avoided. This column gets added as the last column in the leaf level pages and is not sorted. It will not be added to intermediate or root level. As an outcome, modifying this INCLUDE column does not move rows around because it is not sorted.
To summarize, if a column is in the SELECT, then it can be added as INCLUDE column in the index.
Though adding a column as INCLUDE optimizes the performance of the queries, it is also important to be aware of the disadvantages to it.
Cons of Covering index:
a. Increases the leaf level row size and the number of data pages in both disk and memory, which in turn increases database size.
b. Query needs to read or scan more leaf level pages in the index.
c. Additional overhead during index maintenance
So when you need to modify an index, make sure you understand the pros and cons of adding the columns as a key or INCLUDE.
No matter what, adding a column to key or INCLUDE makes the index larger.
I want to show demos but don’t want to make this article anymore bigger, so I’ll demo in the next article.
Summary: When you have a column in the filter clause, you want the column data to be sorted in the index, so Optimizer can go seek right at the page where the row is located and retrieve the values. Data can get sorted only if the column is part of the first few index key columns(mostly first or second column). Key columns get added to root and intermediate level pages of the index. So, if you are looking to index a column in the filter clause, add that column as part of the index key columns.
When you have a column in the SELECT, then this column can be added as an INCLUDE column, since this column data doesn't have to be sorted and all you need is to have the data of this column in the index, so lookups to the clustered index(which has all columns)can be avoided. When a column is part of INCLUDE, it gets added as the last column in the leaf level pages and is not sorted. It will not be added to intermediate or root level. Also, modifying this INCLUDE column does not move rows around because it is not sorted.
That being said, this is not a hard and fast rule of how to create indexes and does not apply to all situations.
You should focus on creating an index that will narrow your search space, seek the values needed and cover the columns in the query.
By no means is INCLUDE cheaper, adding a column as a key column or INCLUDE is going to make the index bigger and add to the overhead of maintaining them.
Solid understanding of indexes and their structure is important. Best indexing strategy always depends on the environment and its workload.
Resources: https://www.brentozar.com/archive/2019/11/how-to-think-like-the-sql-server-engine-should-columns-go-in-the-key-or-the-includes/
https://www.brentozar.com/archive/2019/11/how-to-think-like-the-sql-server-engine-included-columns-arent-free/