

Come on, let’s venture ahead. I'm going to test this on a 2013 StackOverflow database on dbo.Posts table. This table already comes with a clustered index on ID column. I'm going to create a non-clustered index for our demo.
USE StackOverflow
CREATE NONCLUSTERED INDEX IDX_LastEditorDisplayName
ON dbo.Posts (LastEditorDisplayName)
GONow non-clustered index is created, I’m going to run the 2 SELECT queries below, one with LEFT() function in WHERE clause and the other one with LEFT() function in SELECT instead of WHERE.
SELECT ID, LastEditorDisplayName
FROM dbo.Posts
WHERE LEFT(LastEditorDisplayName,3) LIKE 'JIM%'
GO
SELECT ID,
LEFT(LastEditorDisplayName,3)
FROM dbo.Posts
WHERE LastEditorDisplayName LIKE 'JIM%'
GO
Comparison:
1a. First query with LEFT() in WHERE clause: If you look at the execution plan, it is doing a non-clustered index scan to retrieve rows for the WHERE clause. The reason it chose to scan and not seek, is because it needs to check every row of LastEditorDisplayName column in the index and determine if LEFT() of that row value matches ‘JIM’.
By the way, I noticed the name Jim Anderson in the table, and I like the England cricketer James Anderson, so I chose the name Jim for our demo..haha..ok back to work..
The optimizer chose to use the non-clustered index because LastEditorDisplayName is the key column in that index. If there had been another column in the query not covered by the non-clustered index, the optimizer might have opted for a clustered index scan or a combination of non-clustered index scan and key lookups. If the optimizer estimates a large number of lookups, it will prefer a clustered index scan to avoid the overhead of multiple key lookups.
A clustered index scan requires scanning the entire table, whereas a non-clustered index scan is more efficient in this case because the non-clustered index is smaller. Think of the number of pages it has to scan for a clustered index vs non-clustered index. Non-clustered index at any point has lesser number of pages since it does not contain all the columns.
To summarize, we analyzed the behavior when LEFT() is in the where clause and why Optimizer
a. Chose to do a scan instead of seek
b. Chose non-clustered index instead of the clustered index
1b. Second query with LEFT() in SELECT: If you look at the execution plan, you’ll see that it uses a non-clustered index seek. This is because the column in the filter clause is the key column of the non-clustered index, and there are no functions applied to this column in the filter clause for it to scan or evaluate at each row of the index. It seeks for value that starts with 'JIM%', which is SARGable(Search ARGument able) because it could go right to the page where values start with JIM as the index is sorted. Then outputs the values to the select and then performs the LEFT() function while displaying the results, which is more efficient, since there is no evaluation needed at every row of index and it can go directly seek and pass the value over.
To summarize, we analyzed why the optimizer chose a seek instead of a scan when LEFT() is in the SELECT clause.
2.Logical reads:
Compare the logical reads between first query where filter clause has a function and second query with no function in filter clause.

These 2 queries return exactly the same rows.
First query where filter clause has LEFT() reads 21960 pages whereas second query with no function in filter clause reads 5 pages, which is a huge difference because of the non-clustered index scan in the first query, where it had to scan every row of non-clustered index vs seek right at the row for the second query.
3.Estimations: Before we dive into the numbers, I’d like to explain a couple of things here.
a. Actual number of rows read: Number of rows that needed to be read from disk/memory
b. Actual number of rows for all executions: Number of rows that are outputted and passed to next operator
c. Estimated number of rows read: Estimated number of rows to be read from disk/memory
d. Estimated number of rows for all executions: Estimated number of rows that will be outputted to next operator
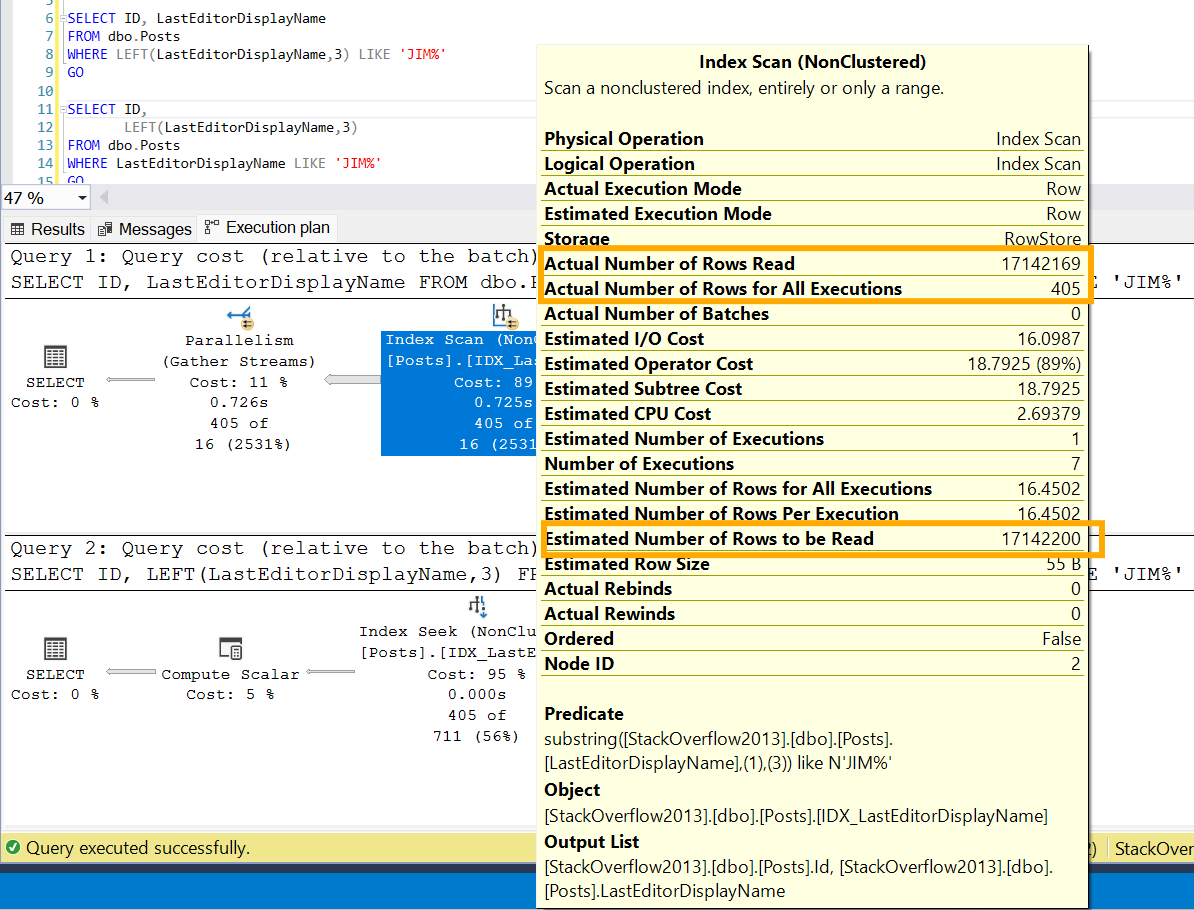
In first query, there are around 17 million rows(which is the whole table) estimated and also read, but only 405 rows are actually outputted and sent to next operator. This is because the Optimizer thinks it needs to fetch all rows and scan the whole index to get the values due to the function in filter clause.

In second query, estimated number of rows are 710 and actual number of rows read and also outputted are 405, the difference is not even 2x, so this is good. In this case, estimations and actual values are close, since it exactly knows what value to seek and output to next operator, when the function is not in the WHERE clause.
In this case, having a function in SELECT instead of WHERE clause did help because the value is SARGable in the WHERE clause when there is no function and it could make use of the non-clustered index. And of course, this doesn’t mean all functions can be moved from WHERE to SELECT.
With DATE* functions you may move them to the other side of the where clause, i.e after = or > or < operator.
WHERE DATEADD(d,5,LastLoginDate) > GETDATE()
to
WHERE LastLoginDate > DATEADD(d,-5,GETDATE()).
You could experiment moving the functions around and while you do so, I suggest doing the following checks:
a. Check execution plan if the index covers the query. I always prefer non-clustered indexes since it has less columns and therefore less pages to read compared to a clustered index scan, which is the whole table and lot more pages. When Optimizer estimates there are going to be many key lookups, it uses the clustered index. So, take advantage of a non-clustered index that covers the query.
b. Check estimations and update statistics if they are outdated.
c. Check actual/estimated number of rows read vs actual/estimated number of rows that are outputted(actual number of rows for all executions). If the difference is huge, then it means the filter condition is non-SARGable.
d. Use SET STATISTICS TIME, IO ON to compare metrics like number of logical reads and execution time.
When you find out that moving the function around gives the same result set along with a seek, less logical reads and less execution time, then you may go ahead.
Conclusion: In most cases, indexes work efficiently when there are no functions in WHERE clause, because it doesn’t have to scan and evaluate each row in the index to match function criteria.
In the demo above, we were able to make use of non-clustered index efficiently by not having the function in WHERE clause and moving the function to SELECT. You could also move some DATE* functions to other side of the WHERE clause for efficient usage of indexes.
A point to note in this case is, when function is used in WHERE clause, non-clustered index is still being used instead of clustered index scan, because the non clustered index is covering the query. So, if you can’t move the function around, check if you can use a non-clustered index that can cover the query so it will at least end up scanning the non-clustered index(a few columns, less pages) instead of scanning a clustered index(whole table aka many pages).
Thanks, if you have read this far. Hope this helps.
Resources: https://www.brentozar.com/archive/2018/12/do-functions-stop-you-from-using-indexes/
https://www.mssqltips.com/sqlservertutorial/3204/avoid-using-functions-in-where-clause/
https://www.brentozar.com/archive/2010/06/sargable-why-string-is-slow/
Thank you 😊 It helps to understand the concept.
Note - James Anderson is the England cricketer not Australian cricketer😜