

This is part 1 of my series on “Insert with TABLOCK hint”
To load data from one table to another table, you can use “INSERT INTO <target_table> SELECT <columns> FROM <source_table>”.
This operation fully logs all records during the insert, which can be time-consuming and cause the transaction log to fill up quickly. To mitigate this, you can use minimal logging, which helps the insert run faster and use less log space. (We will demo all of the points I just said here.)
Fully logged means transaction log keeps track of every row change.
Minimally logged means transaction log keeps track of extent allocations and metadata changes only.
For cases when logging is the bottleneck, minimally logged operation is faster than a fully logged operation because less information is tracked in the transaction log.
For minimal logging to take place, there are a few requirements. The target table must meet the following conditions:
Target database in Simple or Bulk-Logged recovery model
Heap table
Not be part of replication
Use TABLOCK hint
When above requirements are met, then INSERT runs in minimal logging mode which makes the operation faster.
DEMO:
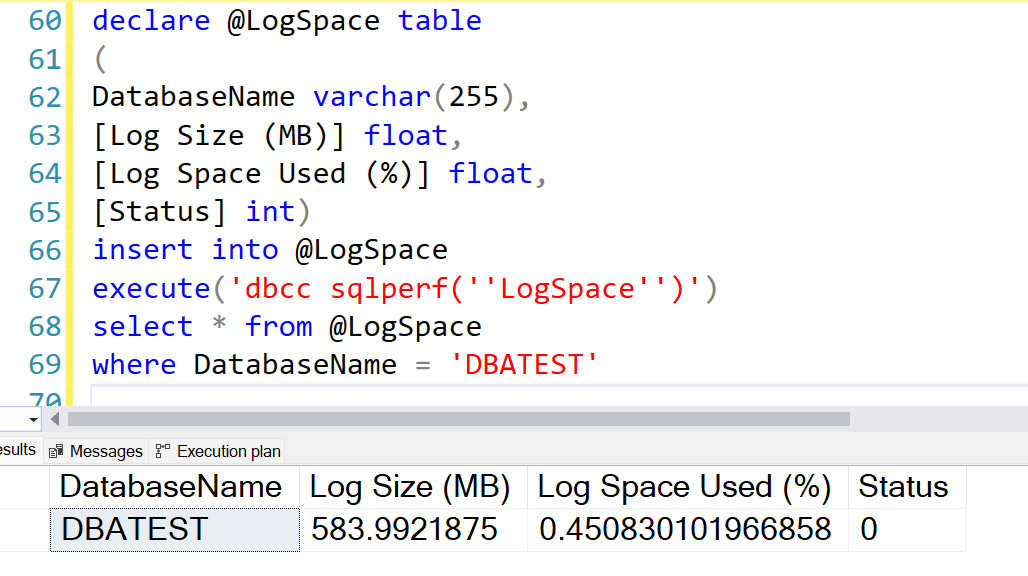
Before going ahead with INSERT, let’s take a note of log space used from logfile so we know how much is changed after the INSERT.
Result: Log file is 0.45% used.--This gives logspace info for all DBs dbcc sqlperf(logspace) --This gives logspace info for database that you specify declare @LogSpace table ( DatabaseName varchar(255), [Log Size (MB)] float, [Log Space Used (%)] float, [Status] int) insert into @LogSpace execute('dbcc sqlperf(''LogSpace'')') select * from @LogSpace where DatabaseName = 'DBATEST'
2. Setup a source table dbo.t1 and populate with 1 million records in it.
(You could use CROSS JOINS on sys.columns to populate data. I’ve been using this query below from StackOverflow for quite some time now, so I decided to go along with it. )/* GET SOURCE TABLE t1 SETUP. THIS SCRIPT CREATES TABLE t1 AND INSERTS 1 MILLION RECORDS FROM sys.columns https://dba.stackexchange.com/questions/130392/generate-and-insert-1-million-rows-into-simple-table */ USE DBATEST GO DROP TABLE IF EXISTS dbo.t1 GO SELECT t1.k AS id ,'a_' + cast(t1.k AS VARCHAR) AS a ,'b_' + cast(t1.k / 2 AS VARCHAR) AS b INTO t1 FROM ( SELECT ROW_NUMBER() OVER ( ORDER BY a.object_id ) AS k FROM sys.all_columns ,sys.all_columns a ) t1 WHERE t1.k < 1000001 --Modify record count insertion as needed3. Setup target table dbo.t2
/* THIS SCRIPT CREATES TARGET TABLE t2, SAME STRUCTURE AS t1. */ USE DBATEST GO DROP TABLE IF EXISTS dbo.t2 GO CREATE TABLE [dbo].[t2]( [id] [bigint] NULL, [a] [varchar](32) NULL, [b] [varchar](32) NULL ) ON [PRIMARY] GO4. Insert 1 million records from source table dbo.t1 to target table dbo.t2. This is a regular insert without the TABLOCK hint.
Result: Time taken = 5 seconds
SET STATISTICS TIME, IO ON
SET NOCOUNT ON
INSERT INTO t2 (id,a,b)
SELECT * FROM t1
Check if rows are fully or minimally logged. I’m checking ‘LOP_INSERT_ROWS’, which is the number of insert records tracked in transaction log.
Result: Fully logged for 1 million records.
SELECT
[Fully Logged Rows] = COUNT_BIG(*)
FROM sys.fn_dblog(NULL, NULL) AS FD
WHERE
FD.Operation = N'LOP_INSERT_ROWS'
AND FD.Context = N'LCX_HEAP'
AND FD.AllocUnitName = N'dbo.t2';
Check how much log space used.
Result: 22% of logfile is used, which is 116 MB.
declare @LogSpace table
(
DatabaseName varchar(255),
[Log Size (MB)] float,
[Log Space Used (%)] float,
[Status] int)
insert into @LogSpace
execute('dbcc sqlperf(''LogSpace'')')
select * from @LogSpace
where DatabaseName = 'DBATEST' 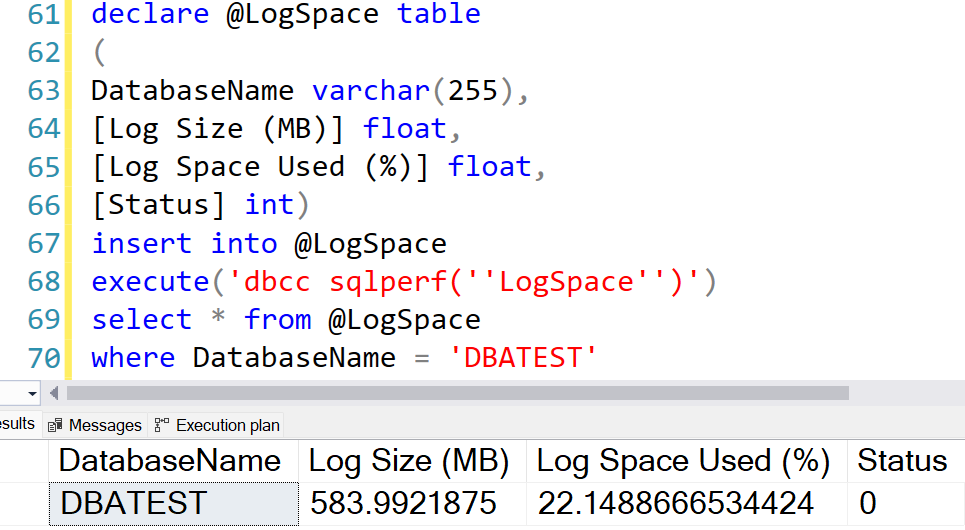
Note, INSERT we ran above is a serial operation, there are no yellow parallel lines and only one thread under “actual number of rows” in the properties.

Let’s reset and create the same environment to perform INSERT WITH (TABLOCK).
Truncate target table dbo.t2 and issue a CHECKPOINT.
TRUNCATE TABLE dbo.t2 CHECKPOINTBefore insert with tablock hint, take note of log file size and rows logged.
Result: 10.5% logfile used and 0 rows logged.


Now environment is set as new to perform INSERT with minimal Logging mode
Let’s check if this target table dbo.t2 is a good candidate for minimal logging. It needs to satisfy 4 requirements:
Heap table - yes, no indexes on this table. More about indexes on part-2.
Not part of replication - yes.
Database in simple or bulk logged recovery model - yes, in simple model.
TABLOCK hint - Adding it now as part of INSERT statement
Run the INSERT with TABLOCK hint to enable minimal logging.
Result: 336 ms
336 ms with TABLOCK hint compared to 4 seconds without the hint. Let’s find out what helped in the next steps.
INSERT INTO t2 WITH (TABLOCK) (id,a,b)
SELECT * FROM t1
Check how many records are fully logged.
Result: 0 records are fully logged and this implies it is minimally logged. Without the hint, all 1 million records were fully logged.
SELECT
[Fully Logged Rows] = COUNT_BIG(*)
FROM sys.fn_dblog(NULL, NULL) AS FD
WHERE
FD.Operation = N'LOP_INSERT_ROWS'
AND FD.Context = N'LCX_HEAP'
AND FD.AllocUnitName = N'dbo.t2';
Check log space used.
Result: Additional log space used is 0.1% vs 15% for fully logged mode.
(when the environment was setup new to use it was 10.5% and after insert with tablock, it is 10.6 %, therefore the increase in logspace used is 0.1%)
Parallelism is enabled for this INSERT operation with TABLOCK. There are yellow parallel lines for the operators in execution plan.
Look at the properties under ‘Actual number of rows’ and there are 7 threads inserting data into the table.


To Summarize:
On an empty heap table:

Above demo was done on an empty heap table. I also repeated the same demo on a non-empty heap table (data -1 million records already in it) and inserted another 1 million records, with and without TABLOCK hint. The results were same as above tabular column for non-heap table too.
INSERT WITH (TABLOCK):
5 times faster runtime
Minimally logged
Less log space used
Parallel insertion
INSERT operation gets faster when it is minimally logged using TABLOCK hint. For minimal logging, the target table must be in a database which is in simple or bulk-logged recovery model and table should not be part of replication.
Bonus:
1. All these also apply to #temp tables.
The above demo was performed in SIMPLE recovery model. I repeated the same demo in FULL recovery model and found that,
INSERTwithTABLOCKhint still ran in less than a second, was minimally logged(in terms of number of records tracked in the transaction log for the insert operation was 0), and enabled parallel insert.The only difference I observed was in the number of pages that were formatted (LOP_FORMAT_PAGE) in the transaction log file. In FULL recovery model, approximately 6,500 pages were formatted, whereas in SIMPLE recovery model, this value was 2. I’d still call it efficiently logged in FULL recovery model as well when TABLOCK hint is used.

I’ll discuss about indexes, locks and parallelism in parts 2 and 3 of this series.
Resources:
Part-2: Insert with TABLOCK hint - Tables with Indexes
https://learn.microsoft.com/en-us/sql/t-sql/statements/insert-transact-sql?view=sql-server-ver16#using-insert-intoselect-to-bulk-import-data-with-minimal-logging-and-parallelism
https://dba.stackexchange.com/questions/130392/generate-and-insert-1-million-rows-into-simple-table
Thanks for reading,
Haripriya.
Hi, Will this option be effective for Azure SQL Database(Full Recovery) as well. Please confirm.
Thanks a lot, really useful indeed