

With keys and indexes in a SQL Server table, sometimes it can get confusing how they are related. A few months ago I was working on setting up a table, I realized that I wasn’t as confused as I used to be. That’s when I thought I should put together an article about keys and indexes for people who might be in the same position as I was.
This article will explore what happens if a primary key is created first, will that result in an index? Or what if you create an index and then add a primary key ? It’s about understanding what happens when you create a key or index, and what the consequences are.
Reference terms:
Primary key: Unique, Non- nullable. Only one key allowed per table.
Unique key: Unique, nullable. Multiple keys are allowed per table.
Clustered index: Physical storage of the table and is sorted according to the clustered key(column).
Non-clustered index: A copy of data of the columns that are part of this index and points to the clustered index using the clustered index key.
Demo
You can try this along with me on a test database if you like.
Scenario 1: Creating a Primary Key on a Heap Table
What happens if you create a primary key on a heap table?
This will result in a clustered index, because that’s how the primary key gets enforced.
Let’s create a heap table
dbo.TestPKwith 10 records and 3 columns:id,a, andb.Then, create a primary key on this heap table.
/*Create a sample table dbo.TestPK with 10 rows*/
USE DBATest;
DROP TABLE IF EXISTS dbo.TestPK;
SELECT
ISNULL(TestPK.k, 0) AS id, -- Ensuring no NULL for the 'id' column
ISNULL('a_' + CAST(TestPK.k AS VARCHAR), '') AS a, -- Ensuring no NULL for 'a' column
ISNULL('b_' + CAST(TestPK.k / 2 AS VARCHAR), '') AS b -- Ensuring no NULL for 'b' column
INTO TestPK
FROM (
SELECT ROW_NUMBER() OVER (
ORDER BY a.object_id
) AS k
FROM sys.all_columns
,sys.all_columns a
) TestPK
WHERE TestPK.k < 11
/*Create Primary Key on this heap table*/
ALTER TABLE dbo.TestPK ADD CONSTRAINT PK_id PRIMARY KEY(id) 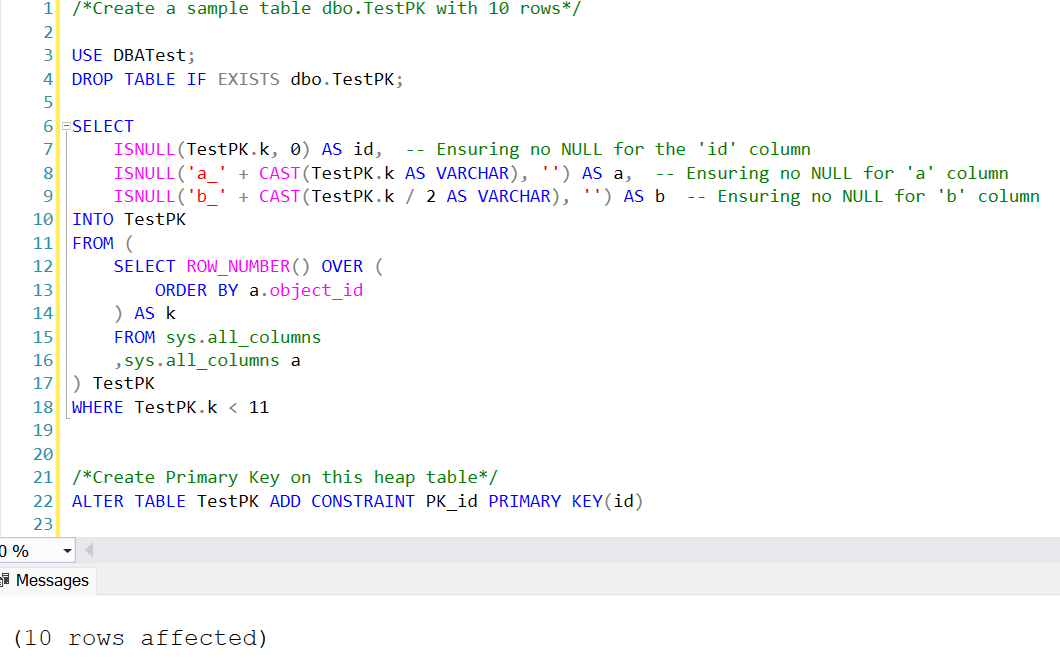
Check table structure
/*Check table structure*/ sp_help TestPK
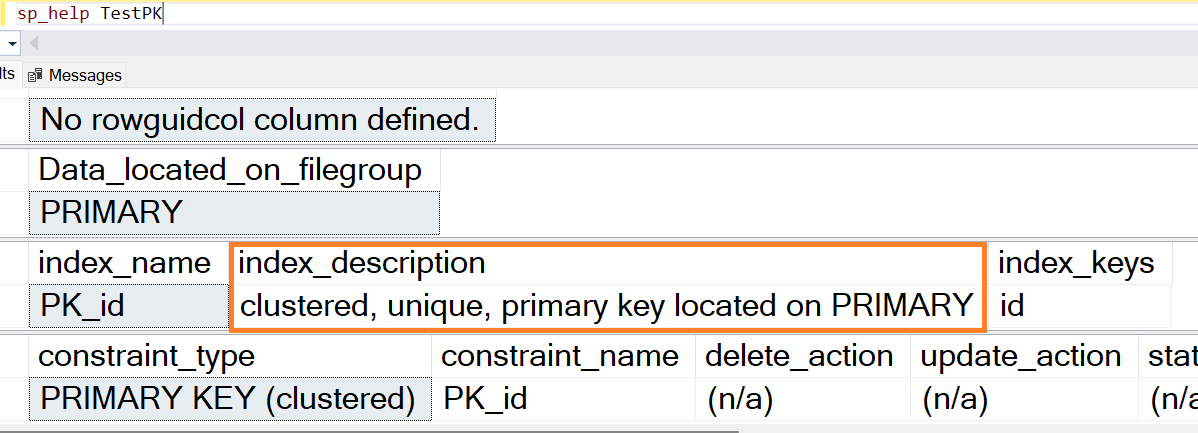
Notice the index_description, it is
Clustered: Creating a primary key defaults to clustered index on a heap table, unless non-clustered is mentioned.
Unique: Because a primary key is a always unique and non nullable.
So, when you create a primary key on a heap table, a clustered index gets created.
Scenario 2: Creating a Clustered Index on a Heap Table (No Primary Key)
Now, what if you create a clustered index on a heap table, without specifying a primary key?
Drop and recreate heap table dbo.TestPK
/*Create a sample table dbo.TestPK with 10 rows*/ USE DBATest; DROP TABLE IF EXISTS dbo.TestPK; SELECT ISNULL(TestPK.k, 0) AS id, -- Ensuring no NULL for the 'id' column ISNULL('a_' + CAST(TestPK.k AS VARCHAR), '') AS a, -- Ensuring no NULL for 'a' column ISNULL('b_' + CAST(TestPK.k / 2 AS VARCHAR), '') AS b -- Ensuring no NULL for 'b' column INTO TestPK FROM ( SELECT ROW_NUMBER() OVER ( ORDER BY a.object_id ) AS k FROM sys.all_columns ,sys.all_columns a ) TestPK WHERE TestPK.k < 11Create a clustered index on column id.
CREATE CLUSTERED INDEX CI_id ON TestPK(id);
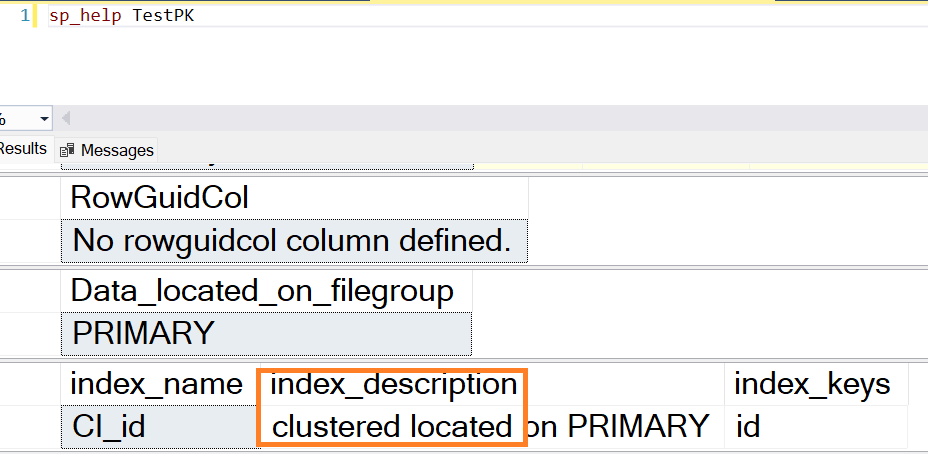
Result:
The table has a clustered index, but there is no primary key on it.
Don’t get confused by the term PRIMARY in the screenshot, that is referred to the primary filegroup.Creating a primary key on a heap table results in a clustered index, but creating a clustered index does not automatically create a primary key.
Scenario 3: Creating a Primary Key on a Table with an Existing Clustered Index
What if you create a primary key on a table that already has a clustered index?
Drop and recreate heap table dbo.TestPK.
/*Create a sample table dbo.TestPK with 10 rows*/ USE DBATest; DROP TABLE IF EXISTS dbo.TestPK; SELECT ISNULL(TestPK.k, 0) AS id, -- Ensuring no NULL for the 'id' column ISNULL('a_' + CAST(TestPK.k AS VARCHAR), '') AS a, -- Ensuring no NULL for 'a' column ISNULL('b_' + CAST(TestPK.k / 2 AS VARCHAR), '') AS b -- Ensuring no NULL for 'b' column INTO TestPK FROM ( SELECT ROW_NUMBER() OVER ( ORDER BY a.object_id ) AS k FROM sys.all_columns ,sys.all_columns a ) TestPK WHERE TestPK.k < 11Create clustered index on column id.
CREATE CLUSTERED INDEX CI_id ON TestPK(id);Create a primary key on a different column, column a.
ALTER TABLE TestPK ADD CONSTRAINT PK_a PRIMARY KEY(a)Check table structure
sp_help TestPK
Result:
Creating a primary key on a clustered table on a different column will result in a unique non-clustered index, since the clustered index is already present in the table. It is unique because primary key has unique values.
Drop existing PK and create a primary key on same column as existing clustered index
/*Drop existing PK*/
ALTER TABLE TestPK DROP CONSTRAINT PK_a
/*Add new PK on same column as existing clustered index*/
ALTER TABLE TestPK ADD CONSTRAINT PK_id PRIMARY KEY(id) Check table structure

Result:
Creating a primary key on same column as existing clustered index, will create a new non-clustered index, which is a duplicate of existing index, as both the indexes are on same columns.
As there can be more than 1 non-clustered index, even if there is already a non-clustered index and a clustered index, creating a primary key will result in an additional unique non-clustered index.
Before you create a key or an index, plan accordingly what is needed so there doesn’t end up being duplicates.
Scenario 4: Dropping the Clustered Index with the Primary Key
What happens if you drop the clustered index, which also has the primary key on it?
Drop and create table with a primary key, this creates a clustered index.
/*Create a sample table dbo.TestPK with 10 rows*/ USE DBATest; DROP TABLE IF EXISTS dbo.TestPK; SELECT ISNULL(TestPK.k, 0) AS id, -- Ensuring no NULL for the 'id' column ISNULL('a_' + CAST(TestPK.k AS VARCHAR), '') AS a, -- Ensuring no NULL for 'a' column ISNULL('b_' + CAST(TestPK.k / 2 AS VARCHAR), '') AS b -- Ensuring no NULL for 'b' column INTO TestPK FROM ( SELECT ROW_NUMBER() OVER ( ORDER BY a.object_id ) AS k FROM sys.all_columns ,sys.all_columns a ) TestPK WHERE TestPK.k < 11 /*Create Primary Key on this heap table*/ ALTER TABLE dbo.TestPK ADD CONSTRAINT PK_id PRIMARY KEY(id)Now, drop clustered index on table dbo.TestPK.
Result: Dropping the clustered index will cause an error if the primary key is still on that column because the primary key depends on the clustered index for enforcement.
DROP INDEX CI_id ON TestPK;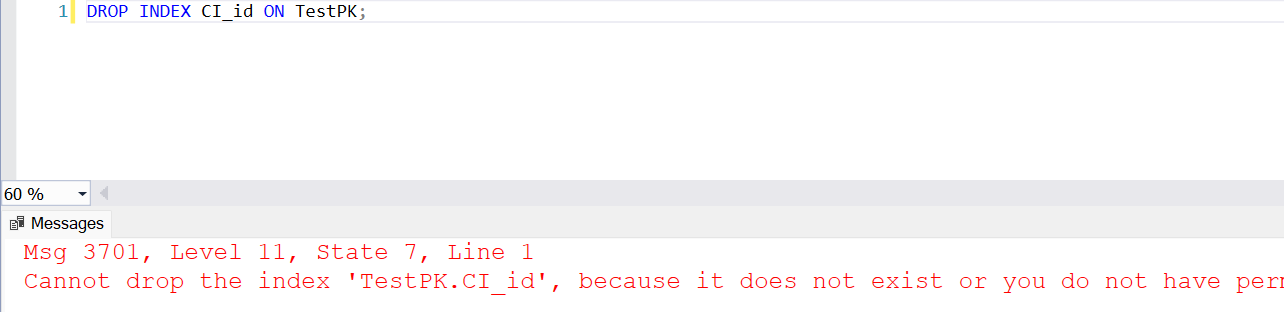
Drop the PK constraint.
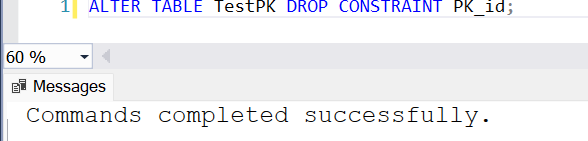
Check table structure.
Result: Dropping the primary key drops the clustered index as well, and is a heap table now.
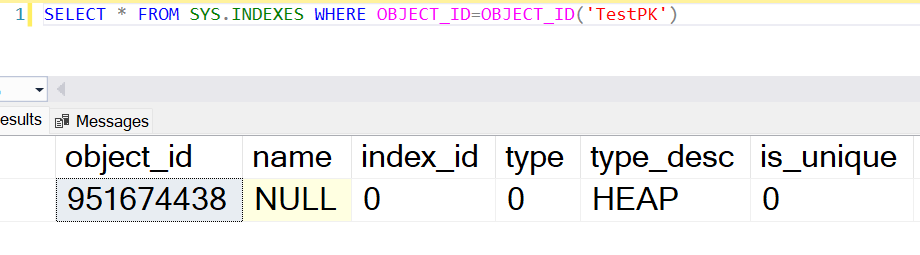
Result:
You must drop the primary key first and that drops its corresponding index, which in this case is a clustered index.
Same applies to non-clustered index as well if it has been enforced using a primary/unique key, the key must be dropped, then the index will be dropped automatically.
Scenario 5
What if you create an unique key on a heap table?
Drop and create table dbo.TestPK and then create an unique key.
/*Create a sample table dbo.TestPK with 10 rows*/ USE DBATest; DROP TABLE IF EXISTS dbo.TestPK; SELECT ISNULL(TestPK.k, 0) AS id, -- Ensuring no NULL for the 'id' column ISNULL('a_' + CAST(TestPK.k AS VARCHAR), '') AS a, -- Ensuring no NULL for 'a' column ISNULL('b_' + CAST(TestPK.k / 2 AS VARCHAR), '') AS b -- Ensuring no NULL for 'b' column INTO TestPK FROM ( SELECT ROW_NUMBER() OVER ( ORDER BY a.object_id ) AS k FROM sys.all_columns ,sys.all_columns a ) TestPK WHERE TestPK.k < 11 /*Create unique key*/ ALTER TABLE dbo.TestPK ADD CONSTRAINT UK_a UNIQUE(a)Check table structure, creating an unique key will always result in an unique non-clustered index, be it on a heap table or a clustered table.

Result: Creating an unique key will always result in an unique non-clustered index.

Summary:
Primary Key on Heap Table: Creates a clustered index to enforce uniqueness.
Clustered Index on Heap Table: Does not automatically create a primary key.
Primary Key on Table with Clustered Index: Creates a unique non-clustered index if a clustered index already exists.
Dropping Clustered Index with Primary Key: Results in an error, you must drop the primary key first.
Dropping Non-Clustered Index with Primary Key: Results in an error, you must drop the primary key first.
Unique Key on Heap Table: Always results in a unique non-clustered index.
Resources:
Thanks for reading,
Haripriya.
My LinkedIn
Thanks for explaining the topics so clearly