
Which is faster? INSERT INTO or SELECT * INTO

Instead of looking at which option is faster, you may want to look at which option is better suited for a given context. Let’s take a look at 2 common options to insert data and analyze them.
INSERT INTO TARGETTABLE
SELECT * FROM SOURCETABLE
OR
SELECT * INTO TARGETTABLE
FROM SOURCETABLE INSERT INTO:
When table already exists and you just want to insert data into this existing table.
These inserts are always serial operations (even when Cost Threshold for Parallelism exceeds), meaning only one thread inserts data into the table, unless TABLOCK or TABLOCKX hints are used.
This operation is fully logged, meaning everything is written in the transaction log, unless temp tables are used as target tables.
As a result, runtime is slower.
DEMO
Create a source table t1 and target table t2 and populate t1 with a million records and t2 empty.
USE DBATEST GO DROP TABLE IF EXISTS dbo.t1 GO --Create table t1 with 1 million records SELECT t1.k AS id ,'a_' + cast(t1.k AS VARCHAR) AS a ,'b_' + cast(t1.k / 2 AS VARCHAR) AS b INTO t1 FROM ( SELECT ROW_NUMBER() OVER ( ORDER BY a.object_id ) AS k FROM sys.all_columns ,sys.all_columns a ) t1 WHERE t1.k < 1000001 --Create empty t2 table DROP TABLE IF EXISTS dbo.t2; CREATE TABLE t2 ( id int, a VARCHAR(20), b VARCHAR(20) ) --Verify counts of t1 and t2 SELECT COUNT(*) AS SourceTable_t1 FROM dbo.t1; SELECT COUNT(*) AS TargetTable_t2 FROM dbo.t2;

2. Perform the insert using INSERT INTO. Look at the ‘Table Insert’ Operator in the execution plan and it is serial operation with one thread inserting all the data.
SET STATISTICS TIME, IO ON
SET NOCOUNT ON
--Clear log
CHECKPOINT
--TURN ON EXEC PLAN
--1. INSERT INTO
USE DBATEST
GO
INSERT INTO t2 (id,a,b)
SELECT * FROM t1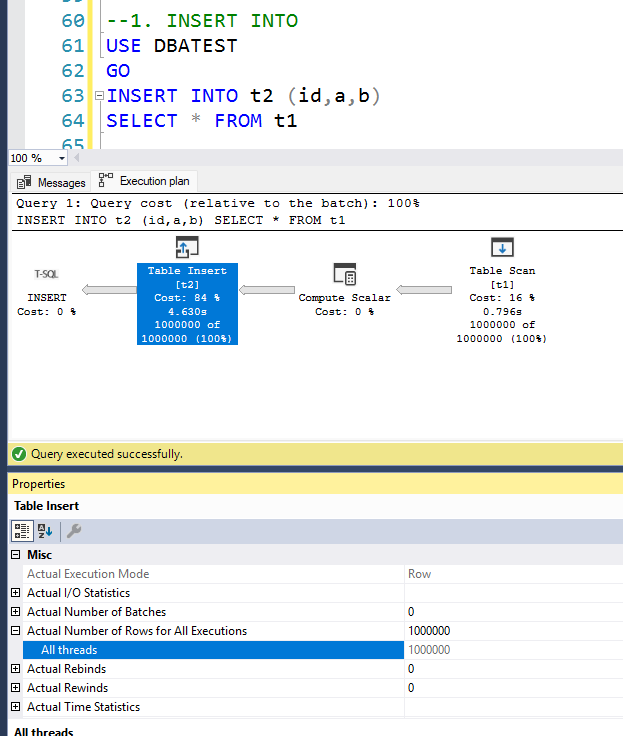
Runtime: 4.8 seconds

Logging: Fully logged, meaning all million rows have been logged in the transaction log.
SELECT Operation, COUNT(*) AS Count FROM sys.fn_dblog(NULL, NULL) WHERE Operation IN (N'LOP_INSERT_ROWS', 'LOP_FORMAT_PAGE') GROUP BY Operation ORDER BY COUNT(*) DESC;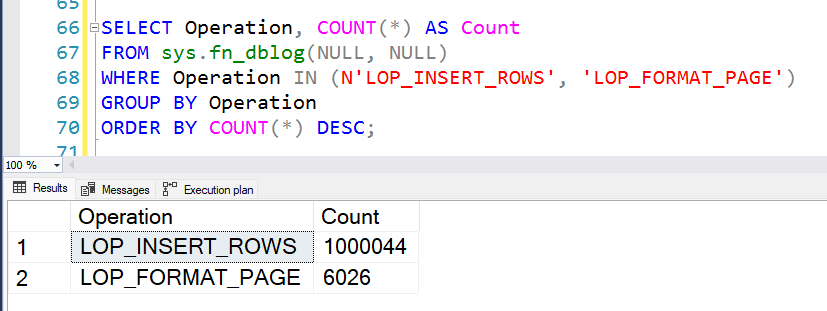

Now, this can be made to run faster when TABLOCK or TABLOCKX hints are used or when temp tables are used as target tables. More about this here -
https://gohigh.substack.com/p/insert-with-tablock-hint-faster
SELECT * INTO:
SQL Server creates the target table same as source table when
SELECT * INTOquery runs.This is a parallel operation when Cost Threshold for Parallelism exceeds.
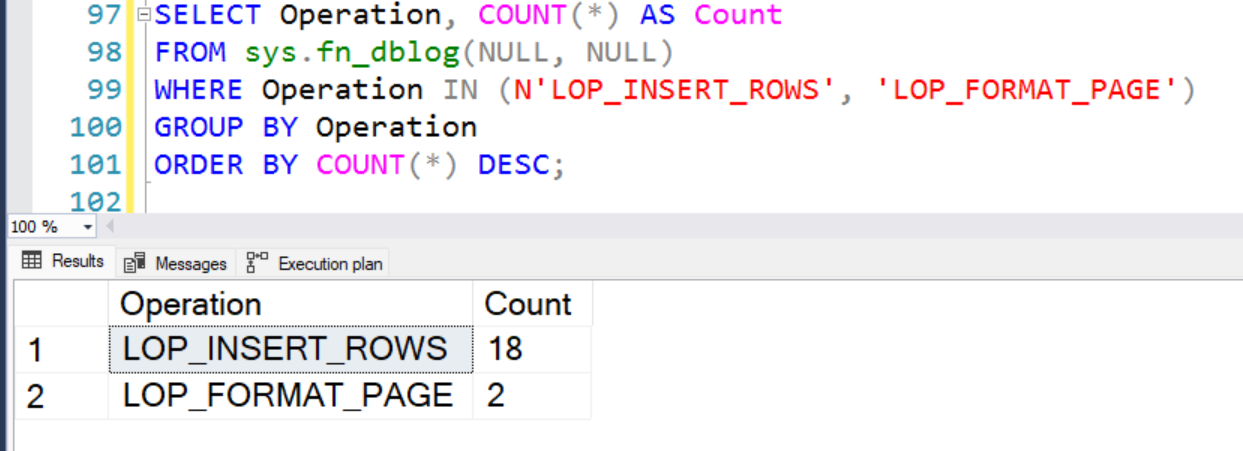
Minimally logged.
As a result, runtime is faster.
Typically used for backups or one-off tasks.
DEMO:
Perform the insert using
SELECT * INTOUSE DBATEST GO DROP TABLE IF EXISTS dbo.t2; --Clear log CHECKPOINT SELECT id,a,b INTO dbo.t2 FROM dbo.t1;Notice that ‘Table Insert’ is a parallel operation with 2 yellow lines. Check properties and you will see that that are 7 multiple threads inserting data into target table.

Runtime = 0.37 seconds, compared to ‘insert into’ which was 4.8 seconds.

4. Logging is minimal.
Conclusion:
SELECT * INTOruns faster because it is minimally logged and operation can go parallel.Comparatively,
INSERT INTOruns slower because it is fully logged and operation is serial.
Summary:
Though
SELECT * INTOruns faster, pick the one that fits your context: schema requirements, logging impact and destination table setup.Use
SELECT * INTOfor quick staging loads, one-off tasks, or lightweight backups where speed matters.Use
INSERT INTOwhen inserting into existing tables that require integrity checks or constraints.To optimize performance with
INSERT INTO, consider usingTABLOCKorTABLOCKXhints when appropriate or use temp tables as target tables.
Additional Reading
To read more about TABLOCK - https://gohigh.substack.com/p/insert-with-tablock-hint-faster
Thanks for reading,
Haripriya.
My LinkedIn