
Why PostgreSQL Needs Connection Pooling and SQL Server Doesn’t


If you speak SQL Server as your first language, then you might be aware that connections are thread-based by design. That means each session/connection in SQL Server gets a worker thread. That thread is tied to that session from start to finish of execution.
If there are no available threads, new connections wait in queue until threads become available. This is called a thread-based model.
Postgres is different, it uses a process-based model. Every single connection spawns a separate backend OS process and each of it consumes RAM (>5MB per connection).
If there are 500 concurrent connections, then that means 500 separate backend processes consuming 2.5-5GB of memory just for connection overhead, before actually doing any work.
For each connection in the background, it has to
Fork a new OS process
Initialize memory
Tear down the process
This takes time and consumes CPU cycles, which is not sustainable with load.
This is where connection pooling becomes useful in Postgres.
When apps don’t use connection pooling with Postgres, the CPU spends all its cycles on “context switching” between processes.
Connection Pooler:
Connection pooling manager limits the number of spawned backends. This is NOT a built-in functionality of Postgres unlike SQL Server.
A popular connection pooling tool is pgBouncer.
It maintains a fixed pool of backend processes already running and reuses them for incoming connections. Instead of:
Fork → Initialize → Use → Tear down (repeat)
With connection pooling:
Fork once → Reuse across hundreds of connections
This means 500 application connections can share just 20-30 backend processes in PostgreSQL, making it closer to how SQL Server handles connections natively.
That being said, AWS RDS Proxy or Azure's built-in poolers remove the need of explicitly adding the connection pooler for cloud managed databases.
Where should the pooler live
Well, there are 3 places we can have a pooler.
App pooling or client side pooling:
The app maintains a pool of connections and reuses them across requests. Every app server has its own pool. It is fast and lightweight as there is no hop in between the app and server. App pooling is the default for most application frameworks, especially in .NET where SQL Server connection pooling is enabled by default via the connection string.
Server side pooling:
A good example here is pgBouncer which sits between the app and database server. All app servers share a single pool.
Cloud pooling:
Cloud manages the pool for you(acts like server side poolers). This is the default in cloud managed database services. Examples are AWS RDS Proxy, Azure SQL Managed Instance connection pooling.
Choose the right mode
Based on how long a connection is held, there are three types of connection pooling you can setup:
Session pooling: Backend connection is held for the entire duration of the session.
Transaction pooling: (most common) Backend connection is held only for the duration of a single transaction and then it is returned to the pool. This is the most common mode as it widely reduces the number of backend connections needed.
Statement pooling: Backend connection is held only for the duration of a single statement which is not recommended to use.
Demo
Alright, I asked Claude Code to come up with demos to show the connection reuse difference with pgBouncer and without it. See the screenshot below.
Direct means without the pooler - 20 client connections spawned 20 backend processes.
With the pooler - the same 20 client connections needed only 4 backend processes, which is a 5x reduction in backend overhead.
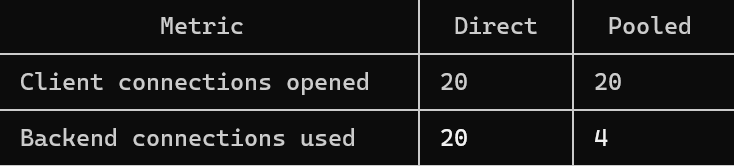
This screenshot shows connection reuse when pooling is enabled.
This means - lower memory usage, fewer context switches and low latency.
Summary
SQL Server uses a thread-based connection model, while PostgreSQL uses a process-based model where each connection spawns a separate OS process and consumes significant memory.
High numbers of short-lived or concurrent PostgreSQL connections cause CPU and memory overhead due to frequent process creation and teardown.
Connection pooling mitigates this by reusing a small number of backend processes across many client connections. PostgreSQL relies on connection pooling managers like pgBouncer for this.
Poolers can live at the application level, server side, or be cloud-managed(e.g., AWS RDS Proxy, Azure-managed poolers).
Pooling modes include session, transaction (most common and efficient), and statement mode.
Thanks for reading,
Haripriya.
Layered pooling is good and also aws recommends it. Just watch out for pooling size per ec2 instance. You have to do the math to make sure you’re not going beyond the max connections limits for rds proxy. Hope that helps, thanks!
Thanks, Haripriya! Great article as always. We implemented RDS Proxy for AWS Aurora and saw good results (AWS suggested pgBouncer if RDS Proxy didn't work well).
In addition to the RDS Proxy database pooling, we have app connection pooling (app is in EC2s)...is that bad or good and any feedback on that?
Thanks!