
Insert with TABLOCK hint - Tables with Indexes
Columnstore index wins!

This is part 2 of my series on “Insert with TABLOCK hint”
In Part 1, we saw how an INSERT with TABLOCK hint runs faster due to minimal logging on a HEAP table. In this post, let’s see how INSERT with TABLOCK hint behaves when there are indexes on the target table.
Scenario
DBATest database is in simple recovery model, and target table dbo.t2 is an empty heap. Before we dive into the demo, I’d like to remind you that INSERT with TABLOCK hint on a heap table completed in less than a second, as demonstrated in Part 1 of this series.
Now, I’ll demonstrate how the behavior changes when the target table has a:
Clustered Index
Non-clustered Index
Columnstore Clustered Index
DEMO 1: Clustered index
Create clustered index on empty target table dbo.t2
CREATE CLUSTERED INDEX CI_ID ON dbo.t2(id);Run insert with
TABLOCKhint.
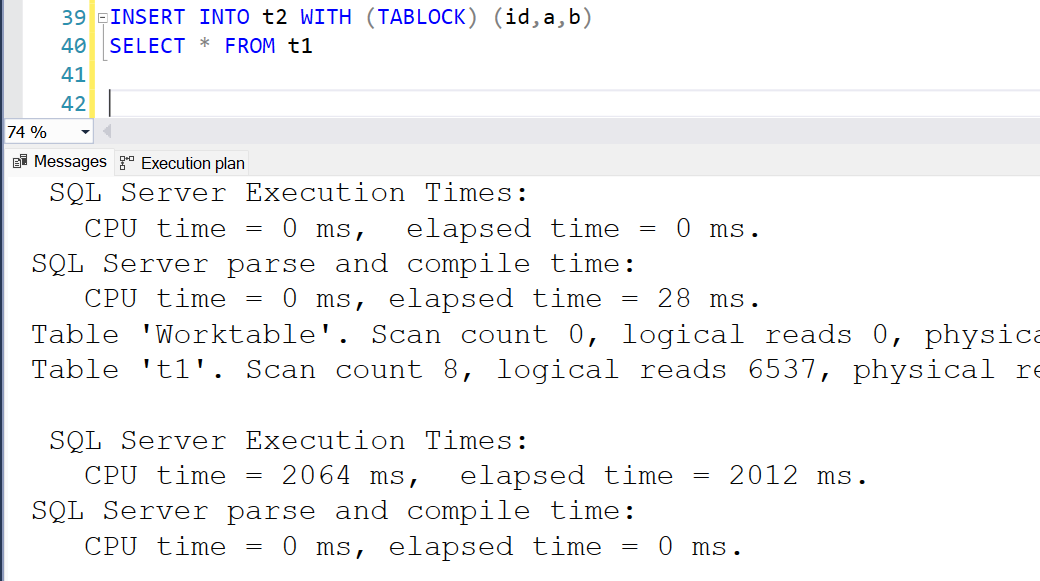
Result: 2 seconds. Insert in this case is a serial operation, because of clustered index, even though the subtree cost is higher than cost threshold for parallelism,
Clustered index disables parallel insert, because to insert data into sorted rows, multiple threads cannot insert and only thread can insert sequentially to maintain the sorted order.INSERT INTO t2 WITH (TABLOCK) (id,a,b) SELECT * FROM t1

Check if this is fully or minimally logged.
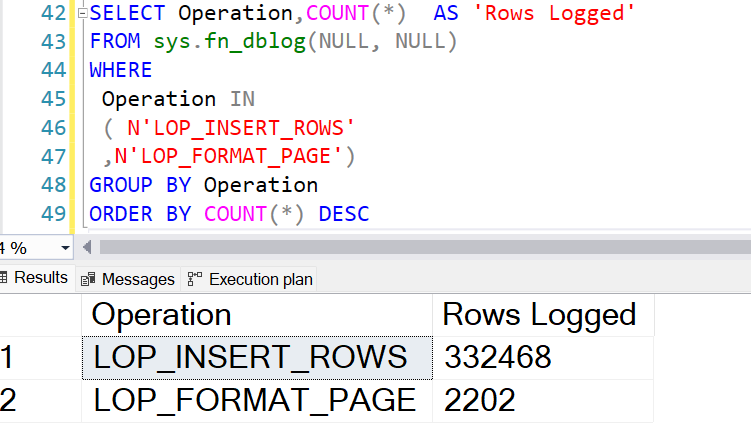
Result: Out of 1 million rows inserted, 332k rows are logged. So, the operation is neither completely fully logged nor minimally logged.
During this operation, 2,202 pages were formatted. But for a heap table, the number of pages formatted were 2 and 0 rows were logged.SELECT Operation,COUNT(*) AS 'Rows Logged' FROM sys.fn_dblog(NULL, NULL) WHERE Operation IN ( N'LOP_INSERT_ROWS' ,N'LOP_FORMAT_PAGE') GROUP BY Operation ORDER BY COUNT(*) DESC
Reset the environment - Drop the index CI_ID ON dbo.t2 and truncate target table dbo.t2 and issue a checkpoint to flush the log.

DROP INDEX CI_ID ON dbo.t2;
TRUNCATE TABLE dbo.t2;
CHECKPOINTWhen there is a clustered index, the runtime is 2 seconds, the operation is serial, and it is neither fully logged nor minimally logged.
DEMO 2: Non-Clustered index
Target table is now heap(reset in previous step) and I’m going to create a non-clustered index.
CREATE NONCLUSTERED INDEX NCI_a ON dbo.t2(a)Run insert with
TABLOCKhint.
Result: 9 seconds with serial insert, again non-clustered index disables parallel insert.
INSERT INTO t2 WITH (TABLOCK) (id,a,b)
SELECT * FROM t1

Check if this is fully or minimally logged.
Result: Fully logged, because along with table data update, it has to update the non-clustered index structure as well which gets fully logged in the transaction log, making the operation run longer.

Reset the environment - Drop the index NCI_a ON dbo.t2 and truncate target table dbo.t2 and issue a checkpoint to flush the log.
DROP INDEX CI_ID ON dbo.t2;
TRUNCATE TABLE dbo.t2;
CHECKPOINTWhen there is a non-clustered index, the runtime is 9 seconds, the operation is serial, and it is fully logged.
DEMO 3: Columnstore Clustered index
Target table is now heap and I’m going to create a columnstore clustered index.
CREATE CLUSTERED COLUMNSTORE INDEX CCI ON dbo.t2Run insert with
TABLOCKhint.
Result: < 1 second, and columnstore clustered index enables parallel insert, due to the structure of this index which is optimized for bulk loading.
INSERT INTO t2 WITH (TABLOCK) (id,a,b)
SELECT * FROM t1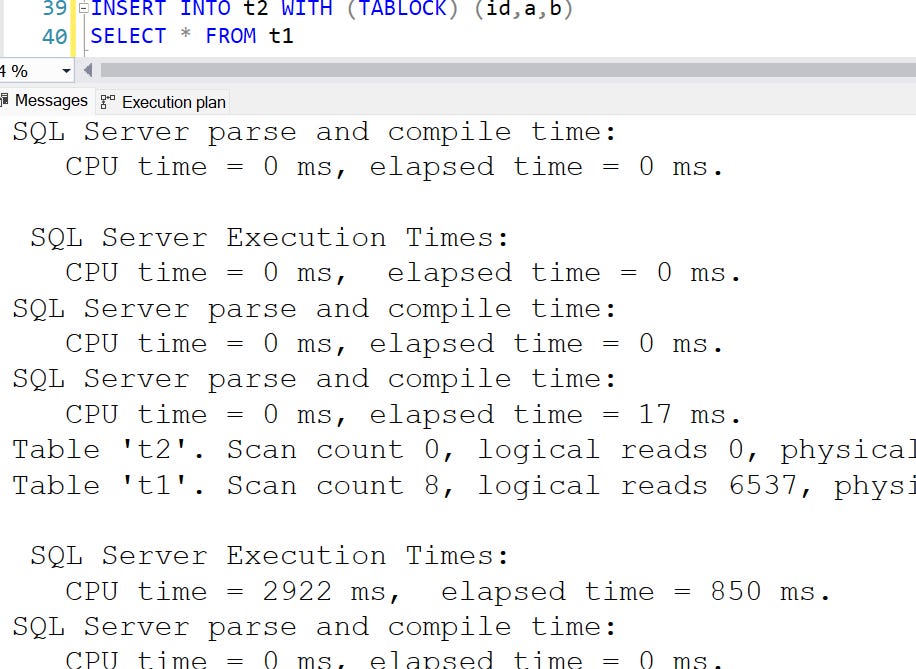

Check if this is fully or minimally logged.
Result: Minimally logged. Only 32 rows are logged out of a million rows and no pages have been formatted.
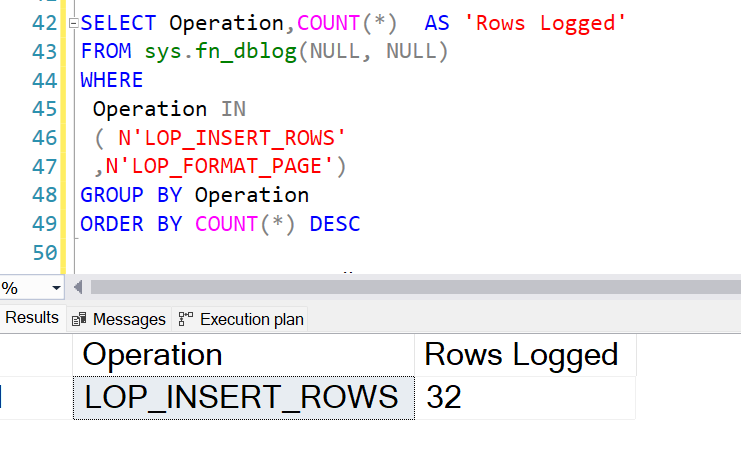
When there is a columnstore clustered index, the runtime is less than a second, the operation is parallel, and it is minimally logged.
Takeaways:
Insert with tablock hint on an empty table:
Clustered columnstore index is the fastest, with minimal logging and parallel insertion.

Insert with tablock hint on a non-empty table:
I performed the same experiment on a non-empty table, with 1 million records already in it. Clustered columnstore index appears to be the fastest and also performed consistently with or without data already in the table.
Inserts on tables with clustered and non-clustered index (in red) have performed poorly on a non-empty table compared to an empty table.

Summary:
When compared to rowstore clustered index, non-clustered index and columnstore index, inserting with TABLOCK hint on a table with a columnstore clustered index results in the fastest runtime, benefiting from minimal logging and parallel insertion.
Resources:
Part-1: Insert with TABLOCK hint - Faster
I wonder how this would fare on a clustered columnstore index with an ordering based on a unique subset of fields?